概要
学習用コーパスからパラメータ(コスト値)を推定することができます. MeCab 自身は品詞体系に非依存な設計になっているため, 独自の品詞体系, 辞書, コーパスに基づく解析器を作成することができます. パラメータ推定には Conditional Random Fields (CRF) を使っています.
処理の流れ
データフロー図は次のようになります.
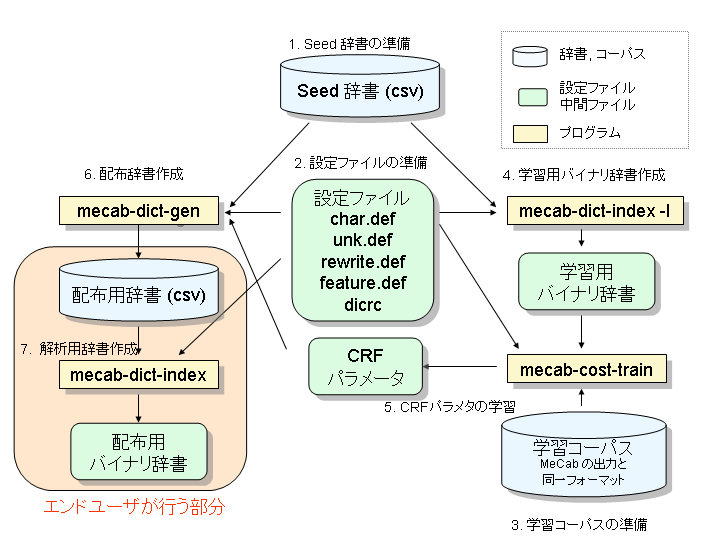
パラメータ推定には以下のサブタスクがあります.
- Seed辞書の準備
- 設定ファイルの準備
- dicrc
- char.def
- unk.def
- rewrite.def
- feature.def
- 学習用コーパスの準備
- 学習用バイナリ辞書の作成
- CRF パラメータの学習
- 配布用辞書の作成
- 解析用バイナリ辞書の作成
- 評価
- 再学習
それぞれ順に説明していきます.
Seed辞書の準備
MeCabの辞書は CSV で記述されます. Seed 辞書と配布辞書のフォーマットは基本的に同一です.
以下が辞書のエントリの例です.
進学校,0,0,0,名詞,一般,*,*,*,*,進学校,シンガクコウ,シンガクコー
梅暦,0,0,0,名詞,一般,*,*,*,*,梅暦,ウメゴヨミ,ウメゴヨミ
気圧,0,0,0,名詞,一般,*,*,*,*,気圧,キアツ,キアツ
水中翼船,0,0,0,名詞,一般,*,*,*,*,水中翼船,スイチュウヨクセン,スイチューヨクセン
最初の4カラム目までは, 必須項目で,
- 表層形 (単語そのもの)
- 左連接状態番号
- 右連接状態番号
- コスト
となっています. 左連接状態番号, 右連接状態番号, コストは, Seed 辞書では 使われないので 0 としておきます.
5カラム目以降は「素性」と呼ばれる項目です. MeCab は, システムの汎用性 を高めるために, 「品詞」「活用」「読み」「発音」といった「単語に付与され る情報」をシステムは区別せず「素性」として扱っています. ユーザは CSV が 許す限り何個でも素性を付与することができます. ただし, 各カラムの素性の 定義はそろえておく必要があります. (5カラム目は品詞, 6カラム目は品詞再分 類等) 通常, 素性番号の若いものから順に一般的な素性を列挙していきます. (例: 品詞, 品詞細分類, 活用型, 活用形, 原形, 読み, 発音)
素性は内部的には配列として扱われます. 0番目の素性, 1番目の素性.. と いう呼び方で素性を参照することがあります. 素性の番号と内部表現(品詞, 読 み等)は, ユーザ自身が管理してください.
上記の例は, ipadic の例です. 素性列として
- 品詞
- 品詞細分類1
- 品詞細分類2
- 品詞細分類3
- 活用型
- 活用形
- 基本形
- 読み
- 発音
が定義されています.
MeCab は活用処理を行いません. 活用する語の場合は, ユーザが事前に活用 を展開する必要があります.
連れ出す,0,0,0,動詞,自立,*,*,五段・サ行,基本形,連れ出す,ツレダス,ツレダス
連れ出さ,0,0,0,動詞,自立,*,*,五段・サ行,未然形,連れ出す,ツレダサ,ツレダサ
連れ出そ,0,0,0,動詞,自立,*,*,五段・サ行,未然ウ接続,連れ出す,ツレダソ,ツレダソ
連れ出し,0,0,0,動詞,自立,*,*,五段・サ行,連用形,連れ出す,ツレダシ,ツレダシ
連れ出せ,0,0,0,動詞,自立,*,*,五段・サ行,仮定形,連れ出す,ツレダセ,ツレダセ
連れ出せ,0,0,0,動詞,自立,*,*,五段・サ行,命令e,連れ出す,ツレダセ,ツレダセ
連れ出しゃ,0,0,0,動詞,自立,*,*,五段・サ行,仮定縮約1,連れ出す,ツレダシャ,ツレダシャ
設定ファイルの準備
dicrc
辞書のさまざまな動作を指定するファイルです. 以下が最低限の設定です.
cost-factor = 800
bos-feature = BOS/EOS,*,*,*,*,*,*,*,*
eval-size = 6
unk-eval-size = 4
config-charset = EUC-JP
cost-factor: コスト値に変換するときのスケーリングファクターです. 700 から 800 で問題ありません.bos-feature: 文頭, 文末の素性です. CSV で表現します.eval-size: 既知語の時, 素性の先頭から何個合致すれば正解と認定するかを指定します.
通常, 既知語は品詞, 活用といった情報のみが正解すればよいので, 「読み」「発音」といった素性は無視するようにします.
上記の例では 6 となっているので, IPA品詞体系の品詞, 品詞細分類1, 2, 3, 活用型, 活用形 の 6つが評価されます.unk-eval-size: 未知語の時, 素性の先頭から何個合致すれば正解と認定するかを指定します.config-charset: dicrc, char.def, unk.def, pos-id.defファイルの文字コードです.
char.def
未知語処理の定義ファイルです. 通常日本語の形態素解析では字種に基づく未知 語処理が行われます. MeCab では, どの文字をどの字種として定義するかといった設 定を細かく指定することができます. さらに, 各字種に対し, どのような未知語 処理を行うか細かく指定することができます.
ファイルの最初には, カテゴリ名の定義と, 各カテゴリの未知語処理の動作 を定義します.
カテゴリ名 動作タイミング(0/1) グルーピング(0/1) 長さ(0,1, 2... n)
- カテゴリ名: カテゴリの名前です.
HIRANA, KATAKANA.. といったカテゴリを定義します.DEFAULT と SPACE は必須のカテゴリです. - 動作タイミング:
そのカテゴリにおいて, いつ未知語処理を動かすかを定義します.
- 0: 既知語がある場合は, 未知語処理を動作させません
- 1: 常に未知語処理を動かします
- グルーピング: 未知語の候補生成方法です.
- 0: 同じ字種でまとめません.
- 1: 同じ字種でまとめます.
- 長さ: 未知語の候補生成方法です.
- 1: 1文字までの文字列を未知語とします.
- 2: 2文字までの文字列を未知語とします.
… - n: n文字までの文字列を未知語とします.
グルーピングと長さは同時に指定することができます.
例
KANJI 0 0 2
SYMBOL 1 1 0
NUMERIC 1 1 0
ALPHA 1 1 0
HIRAGANA 0 1 2
次に, 各カテゴリがUCS2のコードポイントのどこに該当するか定義します.
codepoint デフォルトカテゴリ名 互換カテゴリ名1 互換カテゴリ名2 ..
もしくは,
low_codepoint..high_codepoint デフォルトカテゴリ名 互換カテゴリ名1 互換カテゴリ名2 ..
例
0x0009 SPACE
0x30A1..0x30FF KATAKANA
0x30FC KATAKANA HIRAGANA # ー
コードポイントは UCS2(Unicode)を 0x から始まる16進数で記述します.
最初のカテゴリは, そのコードポイントのデフォルトカテゴリです. さらに, 互換カテゴリを列挙することができます. 上記の例では, 長音記号「ー」 は, デフォルトではカタカナですが, 平仮名を互換カテゴリとして持ちます. グルーピング動作の時に互換カテゴリは同じグループとしてみなされます.
以下が char.def の具体例です.
DEFAULT 0 1 0 # DEFAULT is a mandatory category!
SPACE 0 1 0
KANJI 0 0 2
SYMBOL 1 1 0
NUMERIC 1 1 0
ALPHA 1 1 0
HIRAGANA 0 1 2
KATAKANA 1 1 0
KANJINUMERIC 1 1 0
GREEK 1 1 0
CYRILLIC 1 1 0
# SPACE
0x0020 SPACE # DO NOT REMOVE THIS LINE, 0x0020 is reserved for SPACE
0x00D0 SPACE
0x0009 SPACE
0x000B SPACE
0x000A SPACE
# ASCII
0x0021..0x002F SYMBOL
0x0030..0x0039 NUMERIC
...
# KATAKANA
0x30A1..0x30FF KATAKANA
0x31F0..0x31FF KATAKANA # Small KU .. Small RO
0x30FC KATAKANA HIRAGANA # ー
unk.def
未知語用の辞書です.
DEFAULT,0,0,0,記号,一般,*,*,*,*,*
SPACE,0,0,0,記号,空白,*,*,*,*,*
KANJI,0,0,0,名詞,一般,*,*,*,*,*
KANJI,0,0,0,名詞,サ変接続,*,*,*,*,*
HIRAGANA,0,0,名詞,一般,*,*,*,*,*
HIRAGANA,0,0,0,名詞,サ変接続,*,*,*,*,*
HIRAGANA,0,0,0,名詞,固有名詞,地域,一般,*,*,*
...
表層の部分を char.def で定義したカテゴリ名とした辞書ファイルです. 各カテゴリに対してどのような素生列を付与するかを定義します. 1つのカテゴリに複数の素性を定義してもかまいません. 学習後, 適切なコスト値が 自動的に与えられます.
rewrite.def
素性列から内部状態素生列に変換するマッピングを定義します.
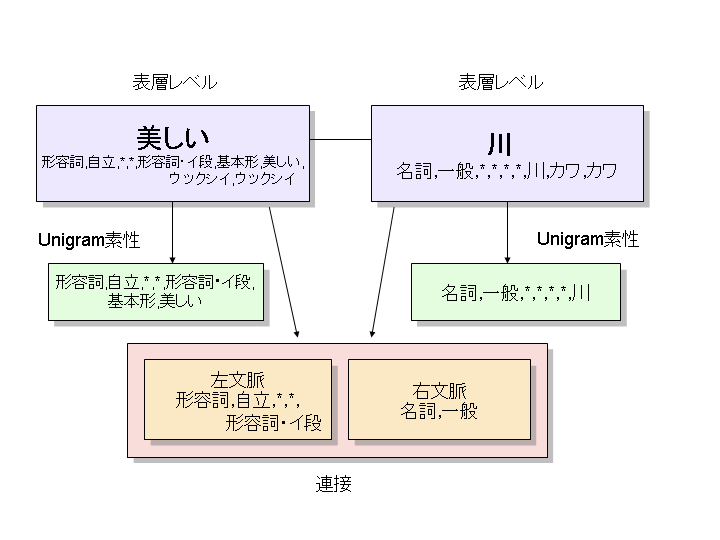
CRFは, unigram, 左文脈 bigram, 右文脈 bigram の3情報を使って統計情報を計
算します. 例えば以下の「美しい川」という以下の例では, 辞書に定義されている素性から unigram素性,
左文脈素性(その形態素を左側から見た時の素性),
右文脈素性(その形態素を左側から見た時の素性)の3つが使われます.
rewrite.def は, 辞書の素性からそれぞれの内部素性へのマッピングを定義します.
具体的に以下のようなことがマッピング関数を適切に定義することで実現できます.
- 「来る」「くる」という二つの表記を「来る」にまとめて統計値を計算する.
- 連接コストの計算の際, 品詞のみを使う/語彙化する…. 等々素性のどの部分を使うかを細かく定義する.
rewrite.def には 3 つのセクションがあります.
[unigram rewrite]: Unigram 内部状態へのマッピング[left rewrite]: 左文脈 bigram へのマッピング[right rewrite]: 右文脈 bigram へのマッピング
それぞれのセクションの後に, 1行に1つのマッピングルールが続きます. マッピングルールは
マッチパターン 変換先
という形式で記述します. マッピングルールは先頭から順に走査されて最初に マッチしたものが使われます.
マッチパターンでは簡単な正規表現がを使うことができます.
*: すべての文字列にマッチ(AB|CD|EF): AB もしくは CD もしくは EF にマッチAB: 文字列 AB のみに完全マッチ
変換先は $1 $2, $3.. というマクロを使い 素性の各要素 (CSVで記された要素)
の内容を参照することができます.
例
[unigram rewrite]
# 読み,発音をとりのぞいて, 品詞1,2,3,4,活用形,活用型,原形,よみ を使う
*,*,*,*,*,*,*,* $1,$2,$3,$4,$5,$6,$7,$8
# 読みがない場合は無視
*,*,*,*,*,*,* $1,$2,$3,$4,$5,$6,$7,*
[left rewrite]
(助詞|助動詞),*,*,*,*,*,(ない|無い) $1,$2,$3,$4,$5,$6,無い
(助詞|助動詞),終助詞,*,*,*,*,(よ|ヨ) $1,$2,$3,$4,$5,$6,よ
...
[right rewrite]
(助詞|助動詞),*,*,*,*,*,(ない|無い) $1,$2,$3,$4,$5,$6,無い
(助詞|助動詞),終助詞,*,*,*,*,(よ|ヨ) $1,$2,$3,$4,$5,$6,よ
..
feature.def
内部状態の素生列から CRFの素生列を抽出するためのテンプレートを定義したファイルです
各行が一テンプレートに対応します. UNIGRAM ではじまるものは UNIGRAM 用のテンプレート, BIGRAM ではじまるものは連接用のテンプレートです.
各テンプレートでは, 以下のマクロを使うことができます
%F[n]: ユニグラムの n番目の素性に展開されます.%F?[n]:ユニグラムの n番目の素性に展開されます. ただし, 未定義の場合そのテンプレートそのものは使われません.%t: 文字種情報に展開されます. 文字種は char.def で定義されたものが使われます. (%t は ユニグラム素性の時のみ有効です)%L[n]: 左文脈の n番目の素性に展開されます.%L?[n]: 左文脈の n番目の素性に展開されます. ただし, 未定義の場合そのテンプレートそのものは使われません.%R[n]: 右文脈の n番目の素性に展開されます.%R?[n]: 左文脈の n番目の素性に展開されます. ただし, 未定義の場合そのテンプレートそのものは使われません.
例
UNIGRAM W0:%F[6]
UNIGRAM W1:%F[0]/%F[6]
UNIGRAM W2:%F[0],%F?[1]/%F[6]
UNIGRAM W3:%F[0],%F[1],%F?[2]/%F[6]
UNIGRAM W4:%F[0],%F[1],%F[2],%F?[3]/%F[6]
UNIGRAM T0:%t
UNIGRAM T1:%F[0]/%t
UNIGRAM T2:%F[0],%F?[1]/%t
UNIGRAM T3:%F[0],%F[1],%F?[2]/%t
UNIGRAM T4:%F[0],%F[1],%F[2],%F?[3]/%t
BIGRAM B00:%L[0]/%R[0]
BIGRAM B01:%L[0],%L?[1]/%R[0]
BIGRAM B02:%L[0]/%R[0],%R?[1]
BIGRAM B03:%L[0]/%R[0],%R[1],%R?[2]
BIGRAM B04:%L[0],%L?[1]/%R[0],%R[1],%R?[2]
BIGRAM B05:%L[0]/%R[0],%R[1],%R[2],%R?[3]
BIGRAM B06:%L[0],%L?[1]/%R[0],%R[1],%R[2],%R?[3]
...
学習用コーパスの準備
学習データは, MeCab のデフォルト出力と同一フォーマットで記述します.
太郎 名詞,固有名詞,人名,名,*,*,太郎,タロウ,タロー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
花子 名詞,固有名詞,人名,名,*,*,花子,ハナコ,ハナコ
が 助詞,格助詞,一般,*,*,*, が,ガ,ガ
好き 名詞,形容動詞語幹,*,*,*,*, 好き,スキ,スキ
だ 助動詞,*,*,*, 特殊・ダ,基本形,だ,ダ,ダ
. 記号,句点,*,*,*,*, . , . , .
EOS
焼酎 名詞,一般,*,*,*,*,焼酎,ショウチュウ,ショーチュー
好き 名詞,形容動詞語幹,*,*,*,*,好き,スキ,スキ
の 助詞,連体化,*,*,*,*, の,ノ,ノ
親父 名詞,一般,*,*,*,*,親父,オヤジ,オヤジ
. 記号,句点,*,*,*,*, . , . , .
EOS
...
タブで区切られた最初の部分が表層文字です. 次に素性配列を CSVで表現した文 字列が続きます. 文の区切りには EOS のみの行を置きます.
学習用バイナリ辞書の作成
現在の作業ディレクトリを WORK とします. WORK 以下に seed と final と いう二つのディレクトリを作ってください.
cd $WORK
mkdir seed final
seed ディレクトリにさきほど説明した以下のファイルをコピーします.
- seed 辞書 (CSV のファイル集合)
- 全設定ファイル (char.def, unk.def, rewrite.def, feature.def)
- 学習用データ (ファイル名: corpus)
例
% cd $WORK/seed
% ls
Adj.csv Interjection.csv Noun.name.csv Noun.verbal.csv Symbol.csv rewrite.def
Adnominal.csv Noun.adjv.csv Noun.number.csv Others.csv Verb.csv unk.def
Adverb.csv Noun.adverbal.csv Noun.org.csv Postp-col.csv char.def
Auxil.csv Noun.csv Noun.others.csv Postp.csv corpus
Conjunction.csv Noun.demonst.csv Noun.place.csv Prefix.csv dicrc
Filler.csv Noun.nai.csv Noun.proper.csv Suffix.csv feature.def
以下のコマンドを実行して, 学習用バイナリ辞書を作成します.
% cd $WORK/seed
% /usr/local/libexec/mecab/mecab-dict-index
以下のように -d, -o を使うこともできます.
% /usr/local/libexec/mecab/mecab-dict-index -d $WORK/seed -o $WORK/seed
-d: seed 辞書, 設定ファイルがあるディレクトリ (デフォルトはカレント)-o: 学習用バイナリ辞書が出力されるディレクトリ (デフォルトはカレント)
CRFパラメータの学習
% cd $WORK/seed
% /usr/local/libexec/mecab/mecab-cost-train -c 1.0 corpus model
以下のように -d を使って辞書を指定することもできます<
% /usr/local/libexec/mecab/mecab-cost-train -d $WORK/seed -c 1.0 $WORK/seed/corpus $WORK/seed/model
-d: 学習用バイナリ辞書があるディレクトリ (デフォルトはカレント)-c: CRF のハイパーパラメータ-f: 素性頻度の閾値-p NUM: NUM 並列で学習を実行 (デフォルトは1)corpus: 学習データのファイル名model: 出力されるCRFパラメータのファイル名
ハイパーパラメータCは, 学習の「強さ」を決めます. C を大きくすると, 学習データにできるだけフィットしようとしますが, 過学習する可能性があります. 小さくすると, 過学習を避けようとしますが, 十分な学習ができない可能性があります. 適切な C は, 交差検定等のモデル選択手法で発見的に見つけるしかありません. デフォルトの値は 1. 0 となっています.
-f オプションによって素性頻度の閾値を指定することができます. 例えば, -f
3 とすると, 学習データ中に3回以上出現した素性のみを使います. 適切な
素性閾値は, 交差検定等のモデル選択手法で発見的に見つけるしかありません.
学習中, 以下のような情報が出力されます.
reading corpus ... adding virtual node: 名詞,固有名詞,地域,一般,*,*,東日,トウニチ,トウニチ
adding virtual node: 副詞,助詞類接続,*,*,*,*,かなり,カナリ,カナリ
Number of sentences: 32
Number of features: 47547
eta: 0.00010
freq: 1
C(sigma^2): 1.00000
iter=0 err=1.00000 F=0.41186 target=1691.68869 diff=1.00000
iter=1 err=1.00000 F=0.68727 target=1077.14848 diff=0.36327
iter=2 err=0.87500 F=0.81904 target=621.20311 diff=0.42329
iter=3 err=0.81250 F=0.86354 target=384.72432 diff=0.38068
iter=4 err=0.68750 F=0.93685 target=233.72722 diff=0.39248
..
- adding virtual node: 未知語処理を行なっても処理できなかった形態素で, 学習の際便宜的に追加される形態素です.
- iter: 学習回数
- err: 文レベルのエラー率
- F: F値(精度と再現率の調和平均)
- target: 目的関数の値. この値が収束すると学習が終了します.
- diff: 目的関数の相対的な差分. この値が 0. 0001 になると学習が終了します.
配布用辞書の作成
% cd $WORK/seed
% /usr/local/libexec/mecab/mecab-dict-gen -o ../final -m model
以下のように -d, -o を使って辞書を指定することもできます
% /usr/local/libexec/mecab/mecab-dict-gen -o $WORK/final -d $WORK/seed -m $WORK/seed/model
-d: seed 辞書があるディレクトリ (デフォルトはカレント)-o: 配布用辞書の出力先ディレクトリ-m: CRF のパラメータファイル
配布用辞書は, seed 辞書と別のディレクトリに出力しなければなりません. 通常, 配布辞書ディレクトリ final をアーカイブしてユーザに配布します.
解析用バイナリ辞書の作成
% cd $WORK/final
% /usr/local/libexec/mecab/mecab-dict-index
以下のように -d, -o を使うこともできます.
% /usr/local/libexec/mecab/mecab-dict-index -d $WORK/final -o $WORK/final
-d: seed 辞書, 設定ファイルがあるディレクトリ (デフォルトはカレント)-o: 学習用バイナリ辞書が出力されるディレクトリ (デフォルトはカレント)
今作った辞書を使って実際に解析してみます.
% mecab -d $WORK/final
焼酎好きの親父.
焼酎 名詞,一般,*,*,*,*,焼酎,ショウチュウ,ショーチュー
好き 名詞,形容動詞語幹,*,*,*,*,好き, スキ, スキ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
親父 名詞,一般,*,*,*,*,親父, オヤジ, オヤジ
. 記号,句点,*,*,*,*,.,.,.
EOS
評価
テストデータを用意します. テストデータは MeCab の デフォルト出力と同一フォーマットで記述します.
まず, mecab-test-gen を使ってテストコーパス(test)から, 文のみ(test.sen)を抽出します.
% /usr/local/libexec/mecab/mecab-test-gen < test > test.sen
test.sen をさきほど作った辞書で解析します.
% mecab -d $WORK/final test.sen > test.result
評価スクリプト mecab-system-eval を実行します. 第一引数がシステムの結果, 第二引数が正解のファイルです.
% /usr/local/libexec/mecab/mecab-system-eval test.result test
precision recall F
LEVEL 0: 98.6887(647112/655710) 98.9793(647112/653785) 98.8338
LEVEL 1: 98.2163(644014/655710) 98.5055(644014/653785) 98.3607
LEVEL 2: 97.2230(637501/655710) 97.5093(637501/653785) 97.3659
LEVEL 4: 96.8367(634968/655710) 97.1218(634968/653785) 96.9791
-l オプションによって, どの素性のレベルを使って評価するか指定できます.
-l 0: 0 番目の素性のみを使って評価します.-l 4: 0〜4 番目の素性を使って評価します-l -1: 全レベルの素性を使って評価します-l "0 1 2"0番目, 0〜1番目, 0〜4番目の3つの評価を表示します.-l "0 1 -1"0番目, 0〜1番目, 全レベルの3つの評価を表示します.
再学習
再学習とは, 現在の学習済みモデルと少量の追加学習データからモデルを再構築する仕組みです.
元の学習データは必要ありません. mecab-ipadic についてはモデルファイルを配布する予定です.
同モデルファイルと, お手元の少量の学習データや追加辞書を用いることで, 簡単なドメイン適応が可能となります.
再学習は, 以下のように -M オプションを用いて以前のモデルファイルを指定します. 初期学習時に用いた seed 辞書に新規語彙を追加しても構いません. corpus は再学習用の新規コーパスです.
% cd $WORK/seed
% /usr/local/libexec/mecab/mecab-cost-train -c 1.0 -M old_model corpus model
以下のように -d を使って辞書を指定することもできます<
% /usr/local/libexec/mecab/mecab-cost-train -M old_model -d $WORK/seed -c 1.0 $WORK/seed/corpus $WORK/seed/model
再学習は, 現在のパラメータをできるだけ変更せずに新しい学習データにできるだけ適応するような学習が行われます. 適応先のコーパスの性質が元のコーパスのそれと大きく変わる場合は、元の学習データに対する精度が低下する恐れがあります. ご了承下さい